READMEにtreeコマンドの結果を書き込むGitHub Actions「readme-tree-writer」を作った
GitHub Marketplaceのリンクはこちら。 github.com
GitHubリポジトリはこちら。 github.com
動機
会社のリポジトリを眺めていると、あるREADMEの中に「そのREADMEが置かれているディレクトリで実行したtreeコマンドの結果」が記載されていました。ディレクトリ構成が情報として重要なコードであったこともあり、確かにそのtreeの結果がREADMEに書かれていると簡単にその情報が得られることもあり便利なものでした。
一方でそれには一つ問題があり、それはすぐにその情報が陳腐化してしまうというものでした。日々の開発の中でディレクトリ構造が変わったりファイルが追加されたりしても書き換え漏れることがあるため、古い情報が記載されたままになっているということが多々発生してしまいます。
そこでGitHub ActionsのようなCIの中で、実際のtreeの実行結果とREADMEの記載内容に差分があるかチェックする、あるいは書き込めるような仕組みが用意できれば上記の問題の解決策になるかなと思い、作成しました。
readme-tree-writer
作成したものは「readme-tree-writer」というGitHub Actionで、本GitHub Actionを導入したリポジトリ内のすべてのREADMEに対し、treeコマンドの結果の記載を更新する というものです。
例えば、以下のようなディレクトリ構成の場合を考えてみます。
some_dir
├── dir1
│ ├── README.md
│ ├── dir1
│ │ └── file
│ └── dir2
│ └── file
└── dir2
├── README.md
└── file
この場合であればreadme-tree-writerはsome_dir/dir1/README.mdとsome_dir/dir2/README.mdを対象とします。
このときsome_dir/dir1/README.mdには以下のような更新を行います。
...
# Tree
\`\`\` # <- 本来はこのバックスラッシュは存在しません。ブログの記法上やむを得ずバックスラッシュを追加しています。
.
├── README.md
├── dir1
│ └── file
└── dir2
└── file
\`\`\`
このようにそれぞれのREADME.mdが置かれているディレクトリでtreeを実行した結果が記載されます。つまりこのsome_dir/dir1/README.mdでは、some_dir/dir1/でのtreeの結果が記載されるわけですね。some_dir/dir2/README.mdについても同様です。
あまり文章で伝えるよりも、実際のサンプルを見てもらうほうがわかりやすいかもしれません。
ユースケース
このreadme-tree-writerを使って実現できるユースケースをいくつかこちらにて紹介します。
1. treeの結果に差分があればfailにしてプルリクエストのstatus checkを落とす
プルリクエストを出したときやcommitを重ねたときに、ファイルやディレクトリの変更があるにも関わらずREADME内の記載が変更されていなければ、status checkをfailにするという使い方が考えられます。こうすることで記載に差分がある状態でmergeできないようする・開発者にREADMEの記載を更新しないといけないことを知らせるなどを見込めます。
あくまで一つの例ですが、workflowの設定は以下のようなものでしょうか。
name: Check tree diff on: push jobs: sample-workflow: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - name: Write tree outputs to README.md uses: shirakiya/readme-tree-writer@v1 with: config_path: .github/readmetreerc.yml - name: Check diff run: | if [ "$(git diff --ignore-space-at-eol . | wc -l)" -gt "0" ]; then echo "Detected diff. See status below:" git --no-pager diff HEAD . git status exit 1 fi
2. treeの結果に差分があれば、その差分を追加でcommit
1のケースと似ていますが、1はチェックするのみに対して追加でcommitを重ねるパターンもありそうです。同様にプルリクエストを出したときに差分があれば、もうGitHub Actionsからその差分をcommitしてもらうことで、更新作業をも自動化できます。
こちらもworkflowの設定の一例を置いておきます。
name: Check and commit tree diff on: push jobs: readme-tree-writer: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - name: Write tree outputs to README uses: shirakiya/readme-tree-writer@v1 - name: Check diff and commit if diff exist run: | if [ "$(git diff --ignore-space-at-eol . | wc -l)" -gt "0" ]; then git config user.name github-actions[bot] git config user.email github-actions[bot]@users.noreply.github.com git commit -am "commit by shirakiya/readme-tree-writer" git push fi
まとめ
今回説明をしていないですが細かい設定等はreadme-tree-writerのドキュメントをご確認ください。treeの結果をREADMEに書かれていてそれをメンテナンスしたいというニーズがどこまであるのか自分でも懐疑的ですが、もし何か機能追加の要望・フィードバック等があればissueを作成していただければと思います。
それでは!
zshのpromptにアクティブなgcloud configrationを表示する
小ネタ的なポストです。
仕事なりプライベートでGCPを使っていると、ターミナルからgcloudコマンドラインツール(以後「gcloudツール」)を使うことにもなろうかと思います。そしてGCPで複数のプロジェクトがあり、それぞれのプロジェクトのリソースに対してgcloudツールから操作する場合、複数の「configration」を設定して操作するプロジェクトに応じて対応するconfigrationをactivateしていることかと思います。
https://cloud.google.com/sdk/docs/configurations
ちなみに私はこのconfigrationの切り替えはpecoで行っています。
chgcp と叩いたらconfigrationのリストがpecoで表示され、選択するとそのconfigrationがactivateされるという動きです。
たったこの4行ぽっちですがはちゃめちゃに便利で効果的に感じていて、これが無いと「ええいgcloudツールを使わないといけないGCPなんて使ってられるかーっ!」と荒々しく叫んでしまいそうです。
便利にしたい欲は絶えない
こうしてアクティブなconfigrationを変更することはカンタンにできるようにしたわけですが、今度はアクティブなconfigrationを確認するのが面倒という気持ちが芽生え始めました。
これは面倒という問題だけでなく、間違ったconfigrationをアクティブにしていたことによりオペミスが発生してしまう可能性が存在する問題です。
そして手っ取り早く「zshのpromptに常に現在アクティブなconfigration名を表示する」という方法でカンタンに確認できるようにしました。実装としては以下のような形です。
load_current_gcp_config() {
local config_path="$HOME/.config/gcloud/active_config"
if [ -f $config_path ]; then
GCP_PROFILE=$(cat $config_path)
fi
}
precmd() {
psvar=()
load_current_gcp_config
psvar[1]=$GCP_PROFILE
}
local p_gcp="[gcp:%1v]"
# 例えば右寄せで表示する
RPROMPT="$p_gcp"
# どこに表示するかは `$p_gcp` を `PROMPT` や `RPROMPT` 変数の差し込む場所で調整できる
実際に使っている筆者の設定はこんな感じです。
https://github.com/shirakiya/dotfiles/blob/master/zshrc#L168-L192
少し解説すると、
load_current_gcp_config で現在アクティブなconfigrationを読み取っています。*1 そしてその load_current_gcp_config を precmd という関数から呼び、configration名が入った GCP_PROFILE を psvar 配列に格納しています。
ここでミソなのが以下のポイントです。
precmd: prompt表示前にフックされる関数psvar: prompt表示時に使える配列。psvar[x]の x にはintegerを与え、PROMPT側では%xvで値を取り出せる
ref. https://zsh.sourceforge.io/Doc/Release/Prompt-Expansion.html#Prompt-Expansion
こんな感じになった
これでpromptに常にアクティブなconfigration名が表示されるようになったので、事故を未然に防げて便利になりました。

*1:もしgcloudツールの仕様変更でファイルパスが変わったりファイル名が変わったりするとこのコードは動かなくなる
bulldozerを導入する
突然ですが、bulldozerが本当に便利なので、その紹介と導入手順について書いていきます。
bulldozerとは
bulldozerはパランティアテクノロジーズが開発したもので、GitHubで使ういわゆるauto-merge botの実装です。bulldozerの機能をおおまかにピックアップすると以下のような機能を持ちます。
- ステータスチェックが通過したpull requestを自動的にmergeする
- pull requestを自動的にベースブランチの最新状態に更新してくれる
bulldozerは GitHub App として動くアプリケーションですが、GitHub Marketplace に公開されているものではないので自前でプライベートなGitHub Appとしてホストする必要があります。GitHub Appとして動くということはつまりpull requestにおける各種アクティビティをhookを受け取り観測できる状態になります。この動きを踏まえて、↑で言っていた動作について少し詳しく説明します。
1. ステータスチェックが通過したpull requestを自動的にmergeする
以下の条件にクリアしていると、bulldozerは自動でそのpull requestのベースブランチへmergeをします。
- Required Status Checkに全てpassしている
- 設定ファイル
bulldozer.ymlに指定したラベル or コメントがそのpull requestに付けられている
具体的に言うと、私の場合はリポジトリの設定的に以下を全て満たす状況になっているとbulldozerが自動的にmergeしてくれます。
- pull requestにapproveが付いていること
- testやlint系のCIが全て通っていること
- pull requestに
ready-to-mergeラベルが付いていること - pull requestに
do-not-mergeラベルが付いていないこと(do-not-mergeをmergeしてはいけないラベルに設定している)
2. pull requestを自動的にベースブランチの最新状態に更新してくれる
Branch protectionで「Require branches to be up to date before merging」の設定を有効にしている場合は、pull requestがベースブランチの最新のcommitを履歴として持っていないと、status checkに落ちてしまいます。そこでbulldozerは存在する全てのpull requestを対象に、自動でそれぞれ最新のベースブランチをheadブランチにmergeし、自動的にpull requestを最新の状態を保ってくれます。
~~~
これらの機能があることで、以下のような嬉しさが生まれることになります。
bulldozer導入前
レビューが完了してmerge可能だけどもCIが完了してなくてmergeできず、後でCIが全部終わってるか確認しに戻ってきてmergeする(あるいはCIが終わってなくてまた後で確認しに戻ってきて...を繰り返すことも) => CI待ちで手間が増える

bulldozer導入後
レビューを終えてapproveな状態だったら特定のラベルorコメントを付けるだけでCIが完了し次第自動的にmergeされる、という状況が作れる。 => CIを待つ必要がなくなる
更に自動的に目的の環境にデプロイされるフローが整備できていれば、レビュー完了時点からその変更が対象の環境に反映されるまで手動のオペレーションが無くなり自動化されたCI/CDが実現できます。
(個人的に特にbulldozerがあって嬉しいと思うのはDependabotやRenovateが複数のpull requestを短期間で作成したときです。それらのpull requestたちにapprove + ラベルを付けていくだけで放っておいたら全てmergeされていたという状態にできますし、auto-mergeと違ってちゃんと目を通したいところには通せる作業フローにできる点でメリットを感じます。)
bulldozer導入手順
こうした便利機能を持つbulldozerですが、上にも書いた通りbulldozerは自前でプライベートなGitHub Appとしてアプリケーションをホストする必要があります(個人的にはここだけが惜しいポイントだなと)。そこで実際に導入する手順を説明していきます。※ bulldozerのREADMEにわりとしっかりめに書いてくれているのでこちらを見るのが基本です
カンタンに作業手順の項目を掻い摘んだ流れだと以下のようなものになります。
- bulldozerのDockerイメージを使ってサーバーを立てる
- GitHub Appとしてインストールする
1. bulldozerのDockerイメージを使ってサーバーを立てる
ありがたいことにbulldozerはDockerイメージを公開してくれているので、このDockerイメージを使って任意の方法でサーバーをたてます。どこにどういう形でサーバーを立てようとも、最終的にGitHubからwebhookのターゲットとして到達可能なURLが得られているとOKです。(筆者の場合はGCPのCloud Runを使って立てました。)
設定ファイルのパスに注意
Dockerイメージを使ってサーバを立てる際の注意点としては、bulldozerの設定ファイルは /secrets/bulldozer.yml に置く必要があることでしょうか。
この公式イメージのDockerfileを見てみると、
CMD ["server", "--config", "/secrets/bulldozer.yml"]
bulldozer/Dockerfile at 625d3f552cdac6ea32bef52fc17fb8ea358393d2 · palantir/bulldozer · GitHub
という起動コマンドが使われていることから、コンテナとして立てる際は以下のどちらかの方法で起動時に設定が反映されるようにしましょう。
- 予め
/secrets/bulldozer.ymlに置いてビルドしたDockerイメージを使う - コンテナ起動時に設定ファイルを
/secrets/bulldozer.ymlにマウントして起動する
そもそも設定ファイル?
bulldozerの設定ファイルは以下に説明付きの例があり、この設定がデフォルトの設定として使われます。
bulldozer/bulldozer.example.yml at 625d3f552cdac6ea32bef52fc17fb8ea358393d2 · palantir/bulldozer · GitHub
わりとしっかりめにコメントを書いてくれているので読めばわかるものだと思います。この設定ファイルでトリガーとなるラベルの値やコメントの値を定義することができます。
色々環境に依るところがありますが、設定例として筆者のものを部分的に載せておきます。
server: address: "0.0.0.0" port: 8080 logging: text: false level: info cache: max_size: 100MB github: web_url: "https://github.com" v3_api_url: "https://api.github.com" options: configuration_path: .bulldozer.yml app_name: bulldozer default_repository_config: ...
必要な環境変数
bulldozerサーバーには以下の3つを環境変数として与える必要があります。
1, 3に関してはGitHub Appとして作成してから取得できる値であるため、ひとまず2の GITHUB_APP_WEBHOOK_SECRET となる値だけ適当に作っておきましょう。
GITHUB_APP_INTEGRATION_ID(GitHub App ID)GITHUB_APP_WEBHOOK_SECRET(Webhook用シークレットとして使われる任意のランダムな文字列)GITHUB_APP_PRIVATE_KEY(GitHub App がアクセストークンを取得するのに必要な秘密鍵)
2. GitHub Appとしてインストールする
作成したサーバーを使って、GitHub Appとしてインストールしていきます。
※ GitHubの公式ドキュメントとしては以下のあたりです。
Installing GitHub Apps - GitHub Docs
Organizationあるいは個人ユーザでも同じ Developer settings セクションにある「GitHub Apps」ページに行くと、「New GitHub App」というボタンがあるのでそこから作成を開始します。

適当に設定していきます。


↑の「Webhook URL」の <your-bulldozer-domain> 等は作成したサーバ環境に応じた値で書き換えてください。
また「Webhook secret」は先ほど作成しておいた値をここで使います。
「permissions」と「Subscribe to events」に関してはREADMEに記載されている通りに設定します。
https://github.com/palantir/bulldozer/tree/625d3f552cdac6ea32bef52fc17fb8ea358393d2#github-app-configuration
これで「Create GitHub App」ボタンを押して作成完了です。
環境変数を更新する
上記で2つの環境変数 GITHUB_APP_INTEGRATION_ID と GITHUB_APP_PRIVATE_KEY が設定できていなかったので設定してきます。
GITHUB_APP_INTEGRATION_ID は作成したGitHub Appページの「About」セクションの「App ID」にある値がそれに当たります。
GITHUB_APP_PRIVATE_KEY は同じページの下の方に↓のような private key を生成できるボタンがあるのでそれを押して秘密鍵ファイルを取得します。そしてその秘密鍵の中身の値をこの環境変数に使います。

サーバーにこれらの新しく更新した環境変数を反映させて(必要なら再起動などを行う)作業完了です。
おそらくこれでbulldozerが正しく稼働し始めたのではないかと思います。
正常に稼働できているかどうかの確認は、サーバーのアクセスログなどからGitHubのwebhookに対してHTTPステータスコード200を返せているかどうかや、実際にプルリクの操作をしてみるなどでしょうか。
まとめ
本当にbulldozerは便利で、それこそ使ったものにしか伝わりづらいのが残念なのですが個人的にはbulldozerがOrganizationにいることが福利厚生とまで思ってしまうほどです。本当にオススメなのでぜひ導入してみてはいかがでしょうか。
メンテモに転職した話
2021年12月23日に、株式会社PKSHA Technologyを退職し、株式会社メンテモに転職しました。
フルタイムのソフトウェアエンジニアとして入社で、フロントエンド・バックエンド限らず小さなスタートアップであるメンテモの開発をどんどん進めていく役割を担います。また、メンテモは山梨県の甲府市にオフィスがありますが、私は東京都市圏に居を構えていることから今回はフルリモートでの採用です。
今回の転職についての振り返りと今後について書いていこうかなと思います。
そもそも私は
このブログなりTwitterなりであまり自己開示してこなかったのですが、私は昔からクルマが好きでした。見るのも乗るのも好きで、ずっと昔からクルマに近いところでWebエンジニアとしてお仕事したいなと思っていました。特に「自分の手でサービスの実装をしてそれを使ってもらう」ことに喜びを感じることもあり、常日頃からこの「自ら実装を行う開発者としてクルマに近いところのお仕事をすること」を意識して生きていきました。「誰と」あるいは「どの会社で」働くかよりも「何を事業をしているのか」の方を重要視しているイメージです。

前職のPKSHA Technologyでは駐車場に関するアプリ開発や、駐車場をより便利に使えるようにするための開発をしていてある程度クルマに近いところでのお仕事はできていたのですが、事業の色としては人々のクルマへの興味・乗りたいという気持ちを加速させるようなものではなく、より駐車場利用をインテリジェントにしていくというものでした。長期的に見ると自動車産業の発展に寄与するものではあるとは思いますが、クルマが中心というよりも駐車場という場所を中心にしたサービス開発になっていくようになるのだろうなと思っていて、クルマに近いように見えてどこか遠さを感じていました。
Twitterの通知でメンテモに出会う
そんなある日、テレビを見つつ晩ごはんを食べ終えようかというところでスマホにTwitterの通知が送られてきました。その通知には「@tagomorisさんが"クルマとITエンジニアのこと"を開いています」(うろ覚え)とあり、普段こうした通知にあまりすぐに反応するタイプではないのですがたまたまスマホの通知が目につき、さらにその内容がクルマ×エンジニアの話題とかなんてど真ん中ストライクなテーマなんだと思い、スペースに参加しました。(Twitterのスペース機能を使うのもこれが初めてでしたし、伝えるのが難しいですが晩ごはん中ではスマホをほぼ見ないのでこの通知をリアルタイムで気づけたのが自分ではなかなか偶然感がありました。)
20:30〜 技術顧問先のメンテモさんの話をSpacesでします!
— tagomoris (@tagomoris) 2021年8月12日
クルマの話とかクルマのサービスの話とか技術の話とかをあれこれ! https://t.co/jJ5XzZhrMU
実際話を聞くと「クルマ×エンジニア」のテーマにはほとんど触れていなくて概ねリモートワークについてのアレコレを話していたので少しばかり肩透かし感があったのですが、このときに初めて「メンテモ」という会社を認知することになりました。そこからホームページやメンテモを紹介する記事等を調べてみて、面白そうなスタートアップだなと思い、8月12日の21:30ぐらいにスペースが終わったのに対してその日の23時にメンテモ代表の若月さん宛にDMを送っていました。

ここからは割とトントン拍子で話が進み、①カジュアル面談 → ②面談 → ③tagomorisさんを交えたコーディング・グループワーク面接 を経て内定をいただけ、先日晴れて入社と相成りました。
実際入社を決めるにあたって少しばかり悩みました。カジュアル面談等を通して、話を聞けば聞くほどメンテモの「クルマに対して貢献したい」という気持ちがどんどん伝わってきましたし、私が常日頃から考えていた「クルマと近いところのお仕事」を超えて「クルマと密着したお仕事」であることでカルチャー部分ではなんら心配していなかったのですが、
- まだ正社員数が2桁にも満たないドスタートアップであること
- 大半の社員が山梨勤務であるのに対し、フルリモートで成果を出せるのか
- 最近家族を持ち子供も考えている中で、こうした不安定さがある場所で不安に押しつぶされないか
等が悩みのポイントで、これらを一言でまとめるとこの「メンテモというリスクを許容できるのか」ということでした。でも個人的にはより理想に向かうためのリスクは取っていくべきだと思っていますし、なにより前職のPKSHAの方々から「いつでも戻ってきてね」という声を掛けていただけたことはとても大きくて、この言葉により深刻なリスクはほぼなくなったと言っても過言ではない状況になったので入社を決めきることができました。本当にPKSHAの方々には感謝感謝です。
メンテモに入社してみて
フルリモートを前提として入社をしましたが、他の社員の皆さんとの距離を詰めることを目的として入社直後の一週間は甲府に滞在して甲府のオフィスへ出社するような働き方をしました。かなり古い学生アパートではあるんですが、宿も用意してくれたので柔軟な対応で助かりました。

実際に入社してみてわかったことは
- みんなクルマが好き
- 体感ベースで雑談の7〜8割はクルマに関連した話
- このクルマが好きという気持ちはホンモノと実感
- やることがいっぱいある、ありすぎるけど開発リソースが足りない
- サービス的に試したい構想がたくさんあるのにできないもどかしさがある
- デプロイフローが確立していなかったり、モニタリングが十分でなかったりと安心しきって寝られないことがたくさんある
- @tagomorisさんと技術相談ができる
- キューイングについて相談すると、色んな実装パターンがスラスラと出てきてマジでビビった
- 本当に甲府にオフィスがある(WEBベンチャーは東京にあると思い込んでる人にとっては本当に甲府にオフィスがあることになかなかビビる)
- 真面目に話すと甲府へ移住するという手段が取れるようになるので、東京での消耗から脱出することができる
- 甲府市への移住支援金事業のサポートが受けられる可能性もある
などでしょうか。
本当に開発リソースが足りていない感じはあり、逆に今はバリバリとモノを作って前に進められる時期なのでイチエンジニアとしてはとても楽しい時期でもあります。
今後について
入社してから行った具体的なお仕事としては、
- Next.js製アプリの本番デプロイができないという深刻な問題の対応
- 依存しなくてもいいものまでモノレポになっていたリソースを分割
- 現状だと意味を成していない CI workflow の削除
等などです。特に1に関しては深刻な問題で、結果として1ヶ月超の期間に渡り本番デプロイができていなかった状況でしたが、新たなマイクロサービスを導入してうんたらかんたらして解決までこぎつけられました。割とハードな実装変更だったのでそれを入社したての私に任せるほど猫の手も借りたいような状態というのがまさにスタートアップですね。
ここから今後については、デプロイフローを作ったりや決済周りの開発だったりをゴリッと進めていきます。現状ほぼ何もないと言ってもいいし、まさに0→1の開発でそこは楽しい・楽しみポイントです。
まとめ
このエントリーでは私のメンテモへの転職について書いてきました。TwitterのSpacesが出会いのきっかけになるなんて思いもしなかったですし、個人的には人生何が起こるかわからないなぁと思い知らされた一件でした。新型コロナウイルスの影響もあって勉強会などで対面で出会う機会が少なくなっている今、こうした非対面での出会いも増えてきていることでしょう。
逆に採用する側の記事も公開されていますので、こちらのエントリもよろしければどうぞ。
メンテモ、一番最初のフルタイムエンジニアはなんと "Twitter Spaces" で採用しました。なかなか面白いチャネルからの採用かと思いますので、ぜひご一読ください!
— 若月佑樹 / メンテモ (@Qrymy) 2022年1月17日
はてなブログに投稿しました #はてなブログ
とあるスタートアップが Twitter Spaces からフルタイムエンジニ…https://t.co/3DPLCpxKdG
もちろんメンテモは絶賛採用中ですので下記リンクからでもそれこそTwitterのDMでもお気軽にお問い合わせください!今なら技術顧問をしてくださっている@tagomorisさんと技術相談をできる機会(これは福利厚生と言っても...?)がありますので、オトクな時期かと思います。
新しいMacBookPro 14インチが届いたのでセットアップした
私が持っているMacBook Proは2016年に購入したもので、そろそろバッテリーの劣化やディスプレイに黒い筋が見えるなど、5年落ちのノートブックPCっぽく少しばかりお疲れな感じになっていました。そのため次に出るMacBook Proのタイミングで新しいものを購入しようと決めていたところ現地時間2021年10月18日に新しいMacBook Proが発表されて、発表が終わった深夜にそのまま注文をしちゃいました。
この瞬間を待っていたんだーっ勢なので新しいMBPポチった pic.twitter.com/d5ykg8Lln6
— shirakiya (@shirakiya831) 2021年10月18日
配送
注文したのが日本時間で10月19日、で手元に届いたのが10月30日と思っていたよりも早く到着しました。

セットアップ
私は以下のリポジトリにmacOS用のセットアップスクリプトを用意していて、READMEの通りに進めていくと開発環境がおおよそ整うというようにしています。これがあることでプライベートで新しいMacを買ったとしても、あるいは職場のMacが新たに支給されたとしても、転職しても、どこでもほぼ同じようにセットアップが進められるのでかなりバリューを発揮してくれています。
このセットアップスクリプト(setup_mac.sh)の内容としては以下のようなことをします。
- いつも使っているHomebrewのパッケージをインストールする
- 自分の dotfilesリポジトリをcloneして必要なsymlinkを貼る
- Macの設定をいくつか行う
- ※本当はここをもっと充実させて「システム環境設定」でポチポチしている部分をスクリプト化したい
いつもの通りこれを使って「Apple Siliconチップになってもうまく通ればいいなぁ」と考えていました。
で実際セットアップをしてみて、使っていたHomebrewパッケージから削除したのが↓の差分で消したものでした。
リストアップすると以下です。
mysql@5.6postgresql- (cask)
java
mysql@5.6
バージョン5.6に限らず、mysql系は完全に対応できていないようです。Homebrewパッケージにおける対応状況は以下のissueにまとめられており参考になります。
5系でないバージョンだと一部機能が使えないだけで一応使うことはできるようですね。ただ、もう最近はMacのOS上にMySQLを立てるのではなく基本的にDockerコンテナを使ってMySQLを立てることが多く、Homebrewパッケージとしては必要ないと思い削除しました。
なおDockerであれば以下のように --platform オプションを入れることでDockerイメージをpullできます。これで動くのであれば問題ないですね。
$ docker pull --platform linux/amd64 mysql:5.6.51
postgresql
postgresqlはインストールには成功しましたが、mysql@5.6と同様にもうDockerコンテナを使わずにpostgresqlを使うこともないと思ったので、こちらも削除しました。
(cask) java
Java界隈のことはよくわかってないのが正直なところなのですが、もうcaskから java は無くなったようですね。他のディストリビューションを入れれば良いようですが、さしあたってJavaは必要でなかったので削除しました。またJavaが必要になるときになんとかするつもりです。
Homebrewのパスが変わった
一番困ったことというか変化を感じたのが、Homebrewでインストールしたパッケージのパスが変わったことでした。
Intelチップ版では /usr/local/ 以下を使ってインストールされ、コマンドなどは /usr/local/bin/ 以下に入るのでここにpathを通していました(デフォルトで /usr/local/bin/ にpathが通っていたかどうかは忘れました)。しかしApple Silicon版では /opt/homebrew に通す必要があります。
The prefix /opt/homebrew was chosen to allow installations in /opt/homebrew for Apple Silicon and /usr/local for Rosetta 2 to coexist and use bottles.
ref. https://docs.brew.sh/FAQ#why-is-the-default-installation-prefix-opthomebrew-on-apple-silicon
私はIntel版のMacを使うこともあり、使用する端末にはすべて同じ自分のdotfilesリポジトリの内容を使うことにしています。そこでIntel版とApple Silicon版に両対応させるために、以下のようにしてHomebrewのpathを環境によって対応させました。
~/.zprofile
# `HOMEBREW_PREFIX` はApple Silicon版にしか定義されない環境変数なので、存在していればこれを使うようにする。
export HOMEBREW_DIR=${HOMEBREW_PREFIX:-"/usr/local"}
if [[ -d "${HOMEBREW_DIR}/opt/mysql-client/bin" ]]; then
export PATH="${HOMEBREW_DIR}/opt/mysql-client/bin:$PATH"
fi
...
セットアップしてみて
実際のところ開発環境を整えるのは、上記のセットアップスクリプトを叩いて終わりではなく、開発観点では例えば
- Vimのpluginのインストール
- iTermのセットアップ(profile作るなど)
- Visual Studio Codeのセットアップ(各種Extensionをダウンロードするなど)
が必要でしたが、さして問題は発生しませんでした。こうしてみるとHomebrewのpath周りが大きく変わったところでしたが逆に大きくハマったところはなく、もうちょっとハマるポイントあるのかなと思っていましたがわりと肩透かし感がありました。Apple M1が登場してから1年近く経ちちゃんと対応してくれてるのはありがたい限りです。
新しいMacで気になるところ
キーボードの打鍵感もバラフライキーボードになる前のに似ていて結構好きで、ノッチも個人的には気にならない。バッテリーの持ちはいいしセットアップもハマらずに済みました。お高い買い物でしたが、割と満足しています。
ただ細かいところで一つ気になるのが、私はmacOSのデスクトップ切り替え(あのMission Controlで増やせるアレ)を多用するのですが、「Control+矢印」あるいはトラックパッドのスワイプでの切り替えが前に比べてなんか遅くなったんですよね。スッと動くのですが、隣のデスクトップに移動してから着地(?)というか操作可能になるまでに以前にはないラグがあり、これがとても気になっています。なんとかする方法があれば助かるのですが、どこかのFAQかフォーラムに投稿しますかね。
ファイル保存毎にコマンドの自動実行ができる modd が便利
modd、あまり多くその存在を聞くことがなかったのですがとても便利なツールだったので、個人的なまとめの意味も込めて紹介します。
moddとは
moddとは ファイル変更を検知して何かしらのコマンドを実行するためのツール です。 例えば、
- コードを変更したら都度テストを実行させたい
- Webアプリケーションのコードを書いているときに、変更を追加したのでサーバを再起動する(livereload)
これらの操作をmoddを使うことによって自動的に行うことができるようになります。
利用例のイメージ
参考までにイメージしやすくなるかもしれないので、moddを利用している時の動きを以下に載せます。
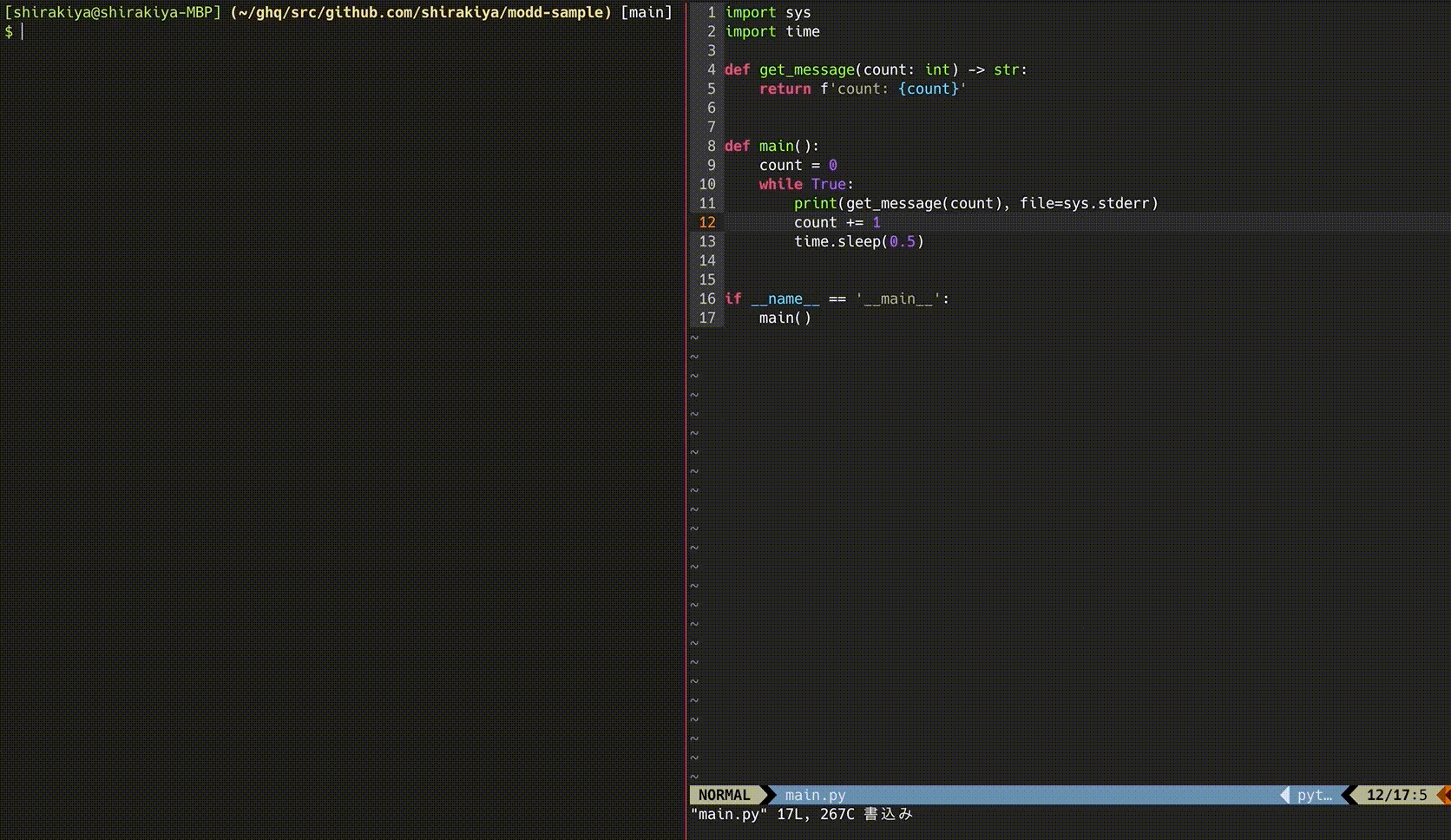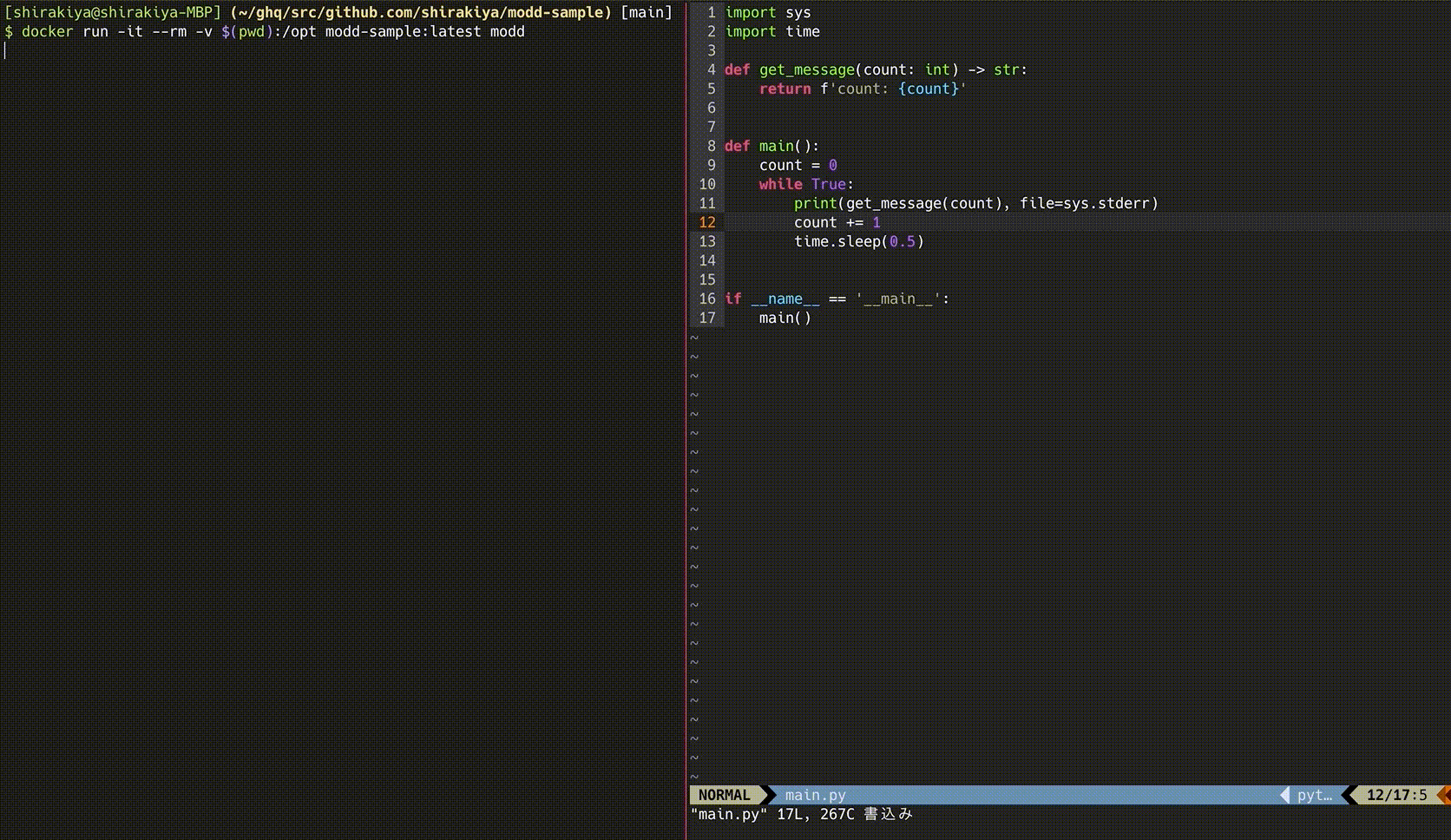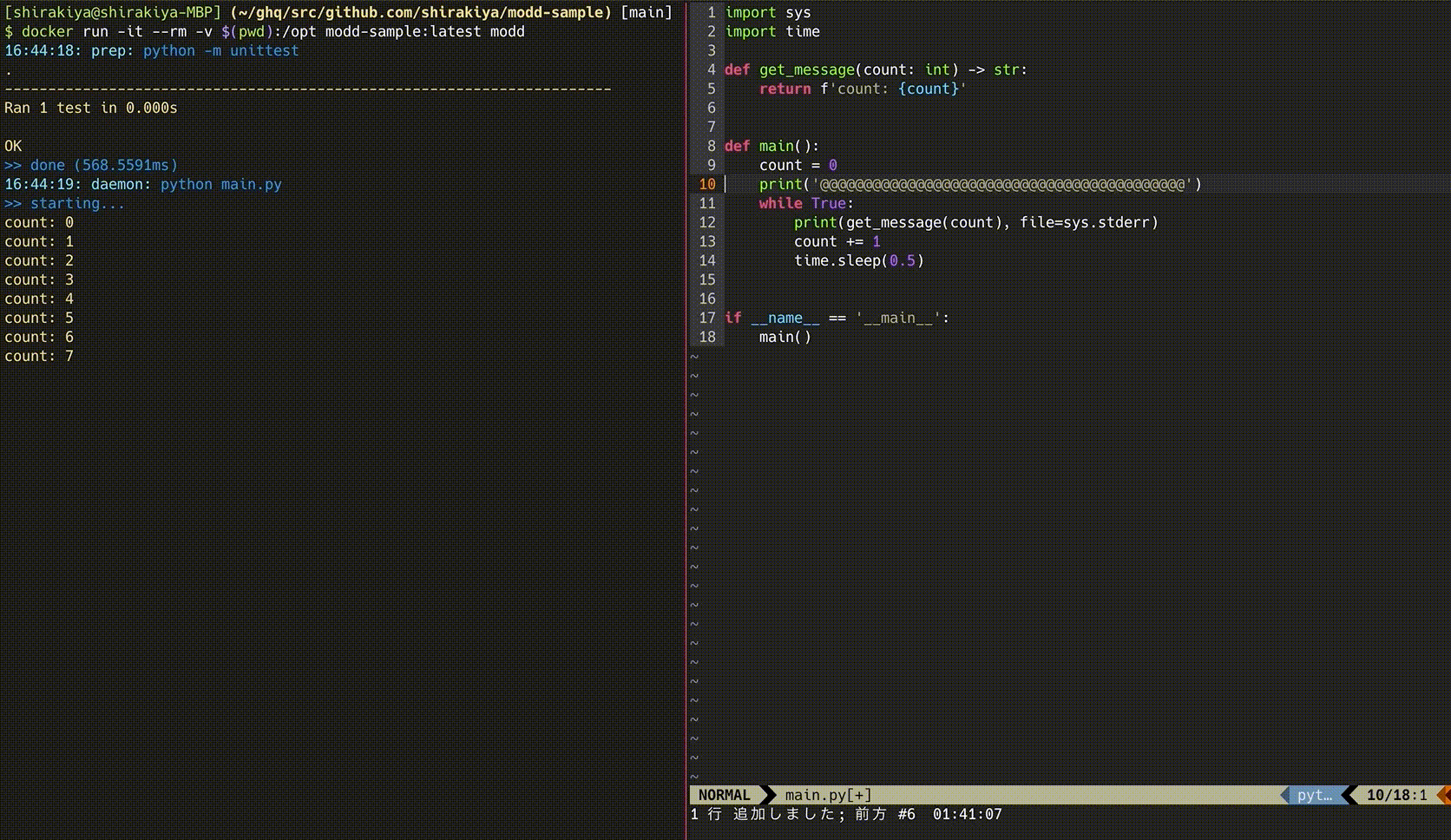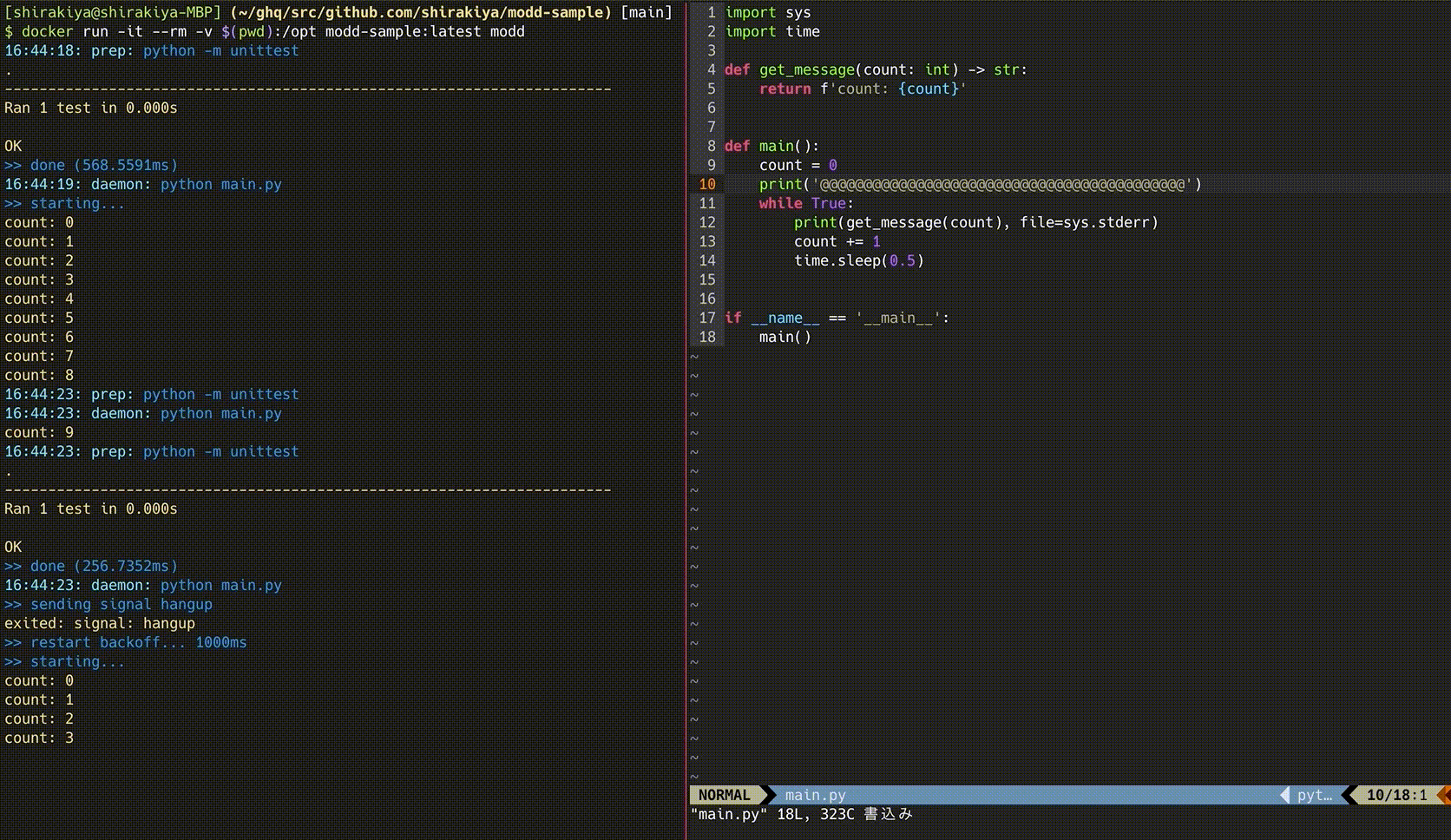
このサンプルは以下のリポジトリに置いています。
インストール
moddの README に書かれています。要点をかい摘むと、
- go get
- Homebrew(macOS)
- releaseパッケージをダウンロード
の3つの方法でmoddを取得することができます。modd自体はGoで書かれているため利用者側も楽で良いですね。
Dockerコンテナで使ってみる
例えば以下のようなDockerfileでビルドするとmoddが使えるイメージを用意できます。
これは主に開発向けのイメージを作ることを意識したDockerfileであり、これはあくまで一つの例であることはご留意ください。
# moddコマンドだけ欲しい状況なので、 # tgzからmoddを取り出すことができるようなstepを入れておくとgoodか FROM alpine:3.12.3 as builder WORKDIR /opt ADD https://github.com/cortesi/modd/releases/download/v0.8/modd-0.8-linux64.tgz . RUN tar xvf modd-0.8-linux64.tgz # goが入っていないイメージの例としてpythonイメージを利用している FROM python:3.9.1 COPY --from=builder /opt/modd-0.8-linux64/modd /usr/local/bin/ # 他の準備... CMD ["modd"]
設定してみる
使うには「どのファイルを検出対象として、どのコマンドを実行するか」の設定をする必要があり、modd.conf ファイルに書きます。( modd.conf はmoddで決められた設定ファイル名のデフォルトであり、modd実行時に --file={file} と指定することで任意のファイル名にすることができます。)
以下にいくつか例を挙げます。しっかり README に書いてくださっているので、詳細についてはそちらを見てみるのがよいです。
ファイル変更を検知してコマンドを実行したい時
*.py {
prep: python -m unittest
}
この例であれば、*.py に該当するファイルが保存されると python -m unittest が実行されます。
コマンドをlivereloadしたい時
*.py {
prep: python -m unittest
daemon: python main.py
}
この例であれば、*.py に該当するファイルが保存されると、その都度 python -m unittest が実行された後に、moddプロセスが管理している子プロセス python [main.py](http://main.py) にSIGHUPシグナルが発行され、再起動します。
※ この設定を使っているのが上記のGIFのものとなります。
起動時に一度だけあるコマンドを実行したい時
{
prep: echo hello
}
この例であれば、 modd の起動時に一度だけ echo hello が実行されます。
このツールの作者でもコントリビュータでもないですが、非常に便利だったので紹介しました。livereloadが実装されたWeb Application Frameworkも多いですが、開発するものはその限りではなく適用できる場面が意外にありとても重宝しているので、作者の方には本当に感謝です。
Google Mapsで任意の場所に指定の距離の円を置けるWebサービスを作った
作ったものはこちらです。名前は「尺々(しゃくしゃく)」と言います。
きっかけ
私が現在働いている会社でもそうなのですが、家賃補助で「会社から〇〇km圏内で××円支給」というのがよくあるかと思います(今まで働いてきた会社ではこうした福利厚生があったのでよくあると言ってますが、世の中的によくあるのかは...?)。
そのときに 会社の住所から〇〇km県内の場所をGoogle Mapsで調べる ことは多々あるかと思いますが、そのときにブラウザで使えるツールで使いやすいものがないなーと常々思っていました。そこで決定版的なツールを作ろうと思ったのがきっかけです。
使い方
尺々は2つの機能があります。以下にそれぞれの機能について軽く説明します。
任意の距離の円を地図に置く
これが基本的なこのサービスの使い道だと思います。会社等の中心を選んで円を落とすことができます。
使い方の流れはこちらの動画をご覧ください。
2住所間の距離を測る
実はGoogle Mapsでもできることではあるのですが、2つの住所間の距離も測定できるようにしてします。会社の住所とこれから借りようとしている部屋の住所の正確な距離を知りたいというような欲求が生まれるかなと思ったためです。
こちらも使い方の流れを動画にしたのでご覧ください。
UIパーツが散らばってないだったり使いやすさ重視で作ってみました。
とのたまっていますが、なにぶん画面デザイン力に乏しいので決定版にはなれてるかは甚だ疑問ですね(自虐)
機能についてなど、なにかご意見等がございましたら @shirakiya831 までお願いします。